Pareto Hobbies 2025
I decided to plot possible hobbies in 2025 in terms of career potential and personal enjoyment.
This is a silly thing to do, but it is also a uniquely software-engineering problem to have - for some reason we seem to be prone to lots of extra curricular learning, quantified self, and a constant need to optimize ourselves for our employability.
As a computer scientist and sometimes hardware hacker, I’m most interested in the following things:
Geospatial ML
I’m fascinated by taking spatial data and running predictors on it. This could be predicitng fine-grained weather patterns, predicting traffic, etc.
At flight science, this has lots of potential applications, so the usefulness is fairly high. I’ve also found that kriging is very useful for robotics though it has been 10 years since I’ve applied it.
Quantum Computing
The recent google announcement has reinvigorated my old interest in quantum computing. A friend from JPL who I highly respect has said QC is at the equivalent of the vaccuum tube era of computing.
Given we’re only now demonstrating benchmark problems, and that most the researchers in those areas are probably hardware and quantum PhDs …. well, I’m a bigshot PhD Computer Scientist, but doubt I could contribute to the field without years of retraining.
Relevance: Very low.
Radar Processing
Super-specific interest, but I want to use and SDR to build a homebrew radar and track boats at the in-laws lake cabin. Why? Who knows.
I’m super comfortable with tracking and estimation, but would need to learn how to extract a “measurement” from the timing and Doppler shift of the radar return.
Given I could see myself working in tracking and estimation in the future, this could be a useful skill.
AWS code as infra
Not very glamorous, but I hate the AWS console and would like to be able to do everything in code.
RL for planning
This is something that is near and dear to my heart. I have been working in planning systems for a while, and have used “RL” (POMDP, etc) in the past, but only as a tangential part of the team.
More generally, the use of end-to-end learned systems for control at least seems to be an increasingly dominant way of doing business. With RL+Planning, my goal is to eventually be able to tradeoff classical estimation and planning with end-to-end systems, and use the best parts of either for a better-than-either pipeline. At the jobs I’ve had I’ve seen a weird false dichotomy that produces decent results once committed, but there’s always this tension that “the other way” is better, producing weird politics.
Most recently, a classical planning pipeline was completely broken by an ML-based estimation of orientation of obstacles. On inspection they were using quite possibly the worst estimator you could use, and ignoring all kinds of good data, because (I think) they were counting on perfect “measurements” from the ML-based vision system. That kind of thing must happen all the time - get stuck in a local minimum of “tune just a little better” when a good filter on top of a noisy estimator could solve all your problems. There’s probably a million such examples in planning systems too.
For discrete, well structured problems with noisy data on them, such as we might encounter in flight science, I think there’s a lot of potential for RL to be extremely useful.
Deep Learning / Large Language Models
I’m not super interested in this, but it seems like a good thing to know.
Ratings
My interest and career potential vary. I’ve rated them on a scale of 1-100, with 100 being the highest.
This is a stupid way to determine hobbies, but I’m doing it anyway.
| Item | Career relevance | Personal Interest |
|---|---|---|
| RL for planning | 50 | 40 |
| DL/LLM in general | 20 | 35 |
| Quantum Computing | 0 | 90 |
| AWS Code as infra | 60 | 10 |
| Radar / signal processing / tracking | 20 | 80 |
| Geospatial ML, kriging, weather data | 80 | 40 |
Results
Here’s the plotted results:
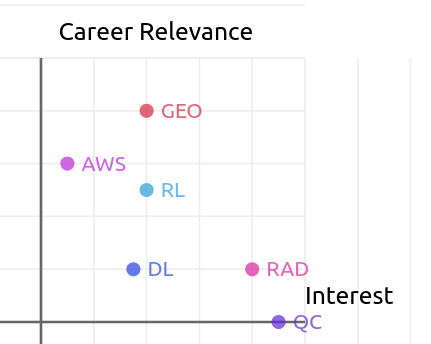
How do we make a decision on this data? As a planning guy, I should be able to do this!
We’ll do a pareto analysis, using the reward function of ||(career_relevance , personal_interest)|| (i.e., magnitude of the vector).
So, let’s plot the pareto frontier for each:
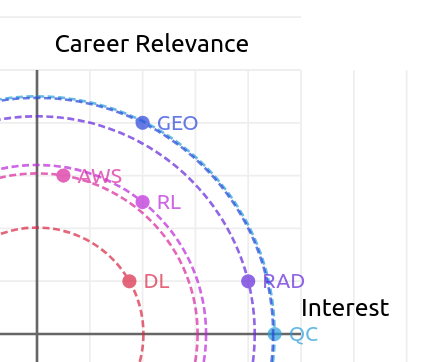
In this case, the outermost circle is the “best”, and a solution “dominates” anything inside its circle. So, according to this, I should focus on Quantum Computing and Geospatial ML. If I had applied scalars to the career relevance and personal interest, those circles would have been ellipses, and the dominance ordering would change. Maybe later.
Comments
I have not configured comments for this site yet as there doesn't seem to be any good, free solutions. Please feel free to email, or reach out on social media if you have any thoughts or questions. I'd love to hear from you!